
Push-to-See: Learning Non-Prehensile Manipulation to Enhance Instance Segmentation via Deep Q-Learning
-
Author:
Baris Serhan, Harit Pandya, Ayse Kucukyilmaz, Gerhard Neumann
-
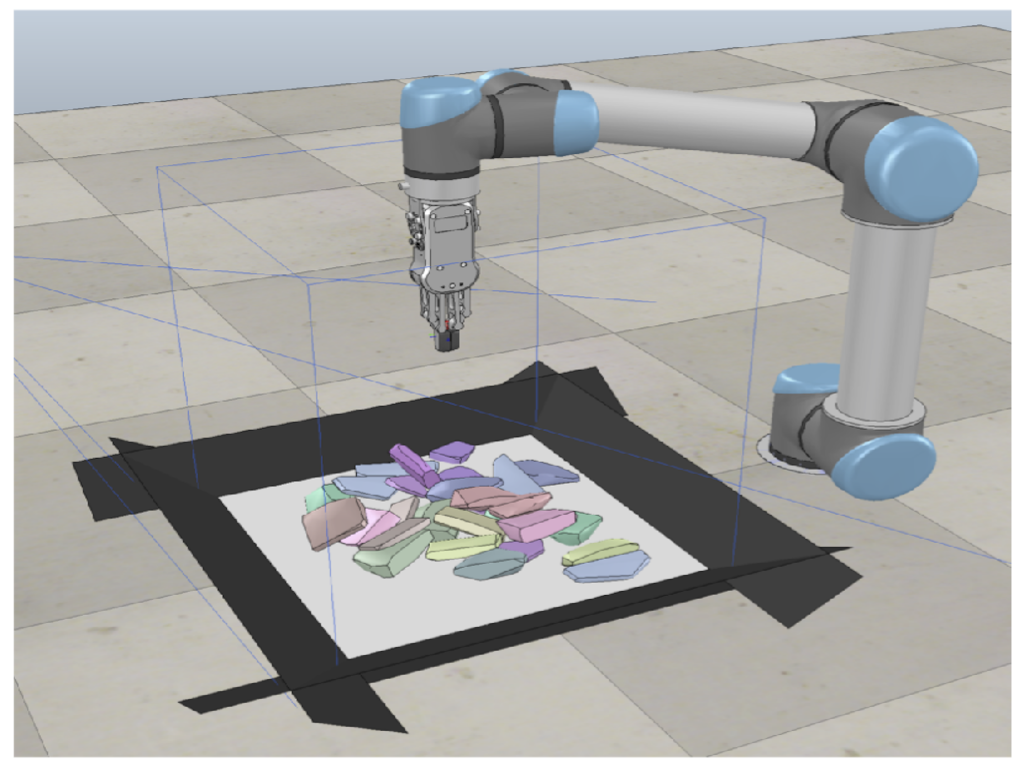
Efficient robotic manipulation of objects for sorting and searching often rely upon how well the objects are
perceived and the available grasp poses. The challenge arises
when the objects are irregular, have similar visual features (e.g.,
textureless objects) and the scene is densely cluttered. In such
cases, non-prehensile manipulation (e.g., pushing) can facilitate
grasping or searching by improving object perception and
singulating the objects from the clutter via physical interaction.
The current robotics literature in interactive segmentation focuses solely on isolated cases, where the central aim is on searching or singulating a single target object, or segmenting sparsely
cluttered scenes, mainly through matching visual futures in
successive scenes before and after the robotic interaction. On
the other hand, in this paper, we introduce the first interactive
segmentation model in the literature that can autonomously
enhance the instance segmentation of such challenging scenes
as a whole via optimising a Q-value function that predicts
appropriate pushing actions for singulation. We achieved this
by training a deep reinforcement learning model with reward
signals generated by a Mask-RCNN trained solely on depth
images. We evaluated our model in experiments by comparing
its success on segmentation quality with a heuristic baseline, as
well as the state-of-the-art Visual Pushing and Grasping (VPG)
model. Our model significantly outperformed both baselines
in all benchmark scenarios. Furthermore, decreasing the segmentation error inherently enabled the autonomous singulation
of the scene as a whole. Our evaluation experiments also serve
as a benchmark for interactive segmentation research.
Link: https://nottingham-repository.worktribe.com/OutputFile/7535013
Video: https://youtu.be/FzdXBJiWWVU